
背景
最近炼丹开始用一块 RTX 3090 (24 G),因为代码里用 ALBERT-base-v2 处理了很多东西导致显存爆炸,于是开始谋求可以节约显存的办法。
网上的一些方法例如及时 del 无用的参数,测试过基本显存占用没有什么变化,也不确定是不是用的方法不对。
之前已经实现了梯度累计,的确可以用 batch_size = 1 占用的显存模拟出 batch_size = n 的情况,但损失的当然是一定的时间,以及如果你用到了 bn 层可能会让模型的效果轻微降低(毕竟多个样本可以一定程度上降低 bias)。
暂时没找到其他有用的方法节约显存,于是想试试混合精度用起来如何。
本文记录一次在 RTX 3090 + pytorch 1.7.0 + cuda 11.1 上的 APEX 安装经历。
合适的 nVidia 驱动与合适的 pytorch
首先确保你的电脑 nVidia 驱动版本支持 RTX 3090,这一点可以在 https://www.nvidia.cn/geforce/drivers/ 查到。
如下图,RTX 3090 最低需要的驱动版本是 455.23,给电脑安装显卡驱动的时候就不要装更低的版本了。

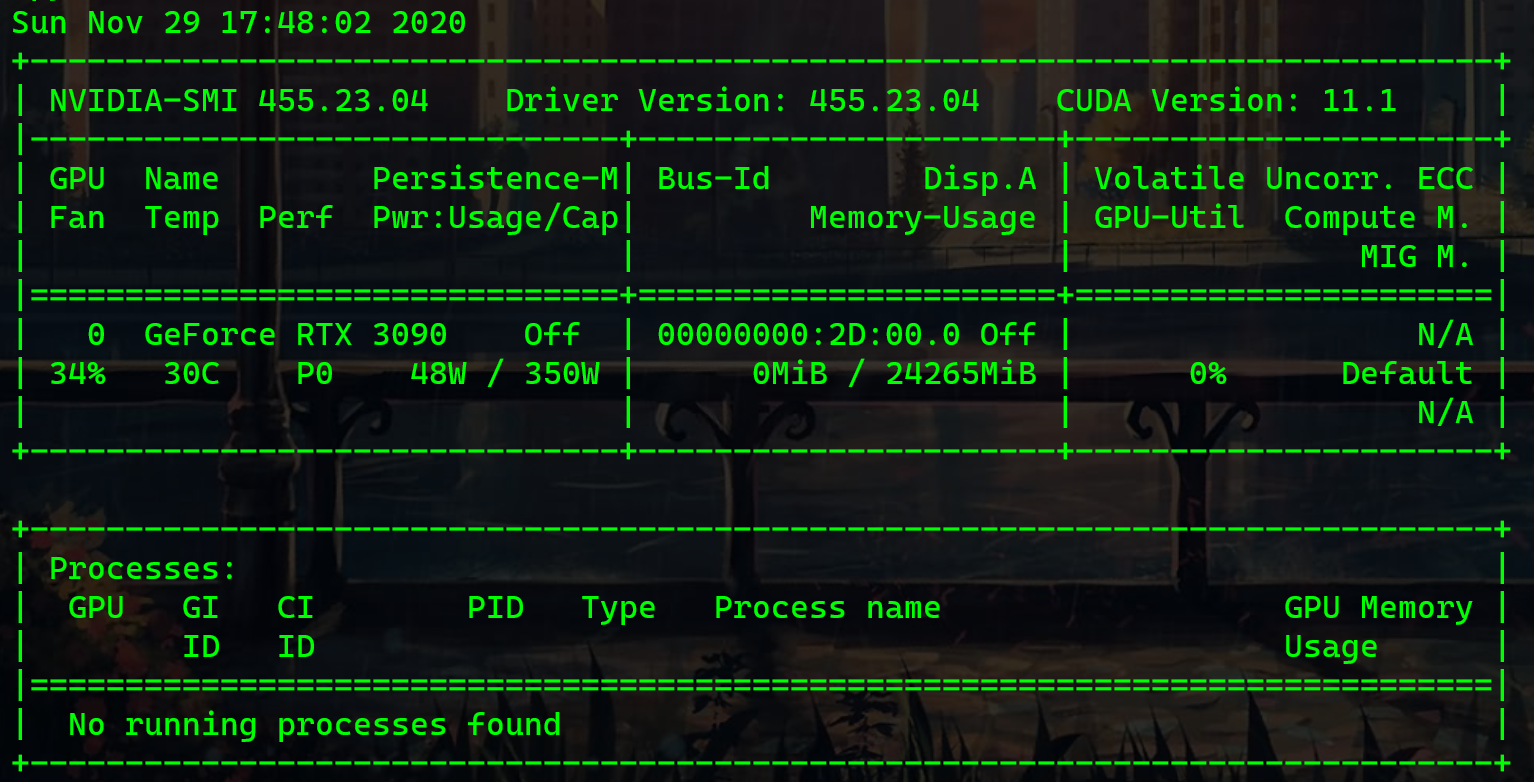
如下图所示,安装完成后执行 nvidia-smi 就可以看到这块显卡了,也能看到 Driver Version: 455.23.04。
然后便是 pytorch 之类的环境,这里推荐使用 conda 来维护所有不同的环境。
30 系列显卡是新一代架构,新驱动不支持 cuda 9 以及 cuda 10,所以必须安装 cuda 11。
目前 pytorch 官网上表示使用 conda 最新可安装的 cudatoolkit 是 11.0 的版本。
conda install pytorch cudatoolkit=11.0 -c pytorch
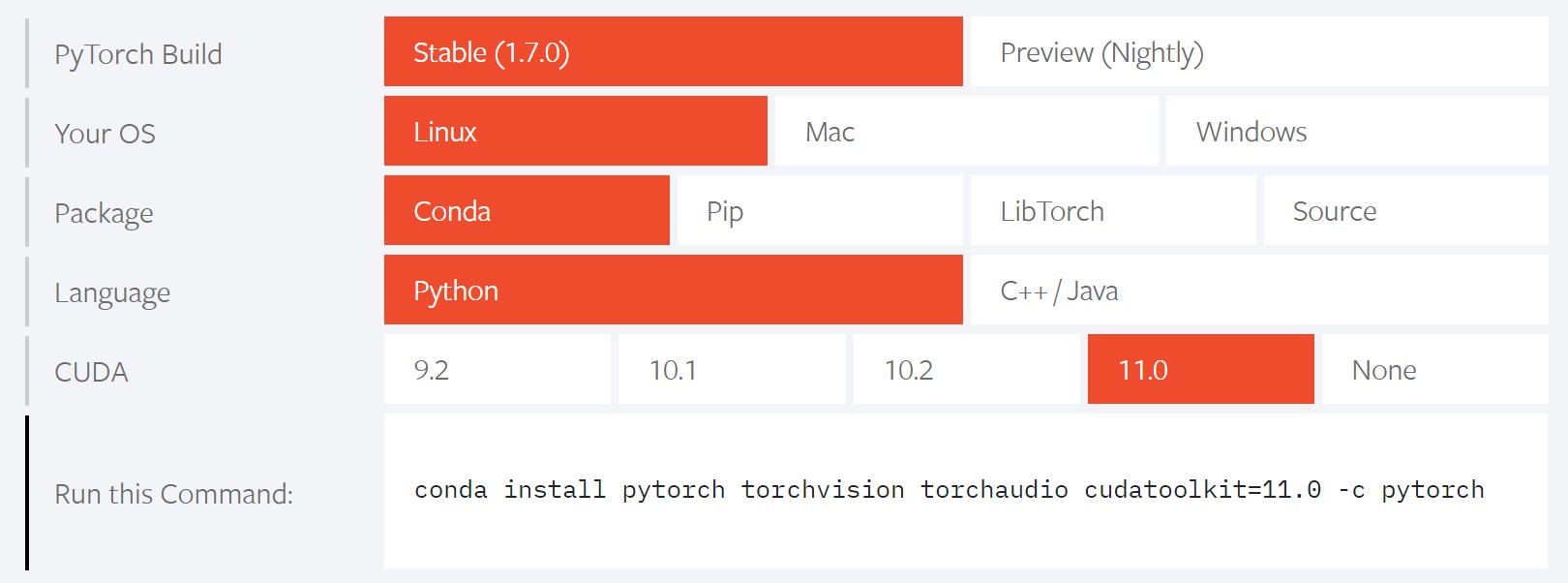
好了,至此基于 cuda 11.0 编译的 pytorch 已经安装完成。接下来是 APEX 的安装。
APEX 安装记录 & CUDA
APEX 官方给的安装其实挺容易的,但实际操作起来可能出现各种坑。
以下是安装 APEX 的方法,记得在执行 pip 时切换到目标虚拟环境(conda activate envs_name)。
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --no-cache-dir --global-option="--pyprof" --global-option="--cpp_ext" --global-option="--cuda_ext" ./
假设你的电脑上没有安装过完整的 cuda(例如仅仅在虚拟环境里安装了 cudatoolkit),那最后一步大概率会说没有找到 nvcc。
nvcc 是 cuda 中提供的一个编译工具,它并不包含在专门针对 pytorch / tensorflow 运行所提供的 cudatoolkit 里。
因此实际上我们还需要 nvcc,我们还需要安装完整的 cuda。
重要的是,针对以上,我们选择哪个版本的 cuda 才能成功安装 apex。
因为刚刚我们提到,在虚拟环境里安装 cudatoolkit 11.0 即可正常使用 RTX 3090。那此时 cuda 版本是否也直接安装为 11.0 即可呢?
这里有一份 cuda 版本与 nVidia 显卡驱动版本的对照表:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
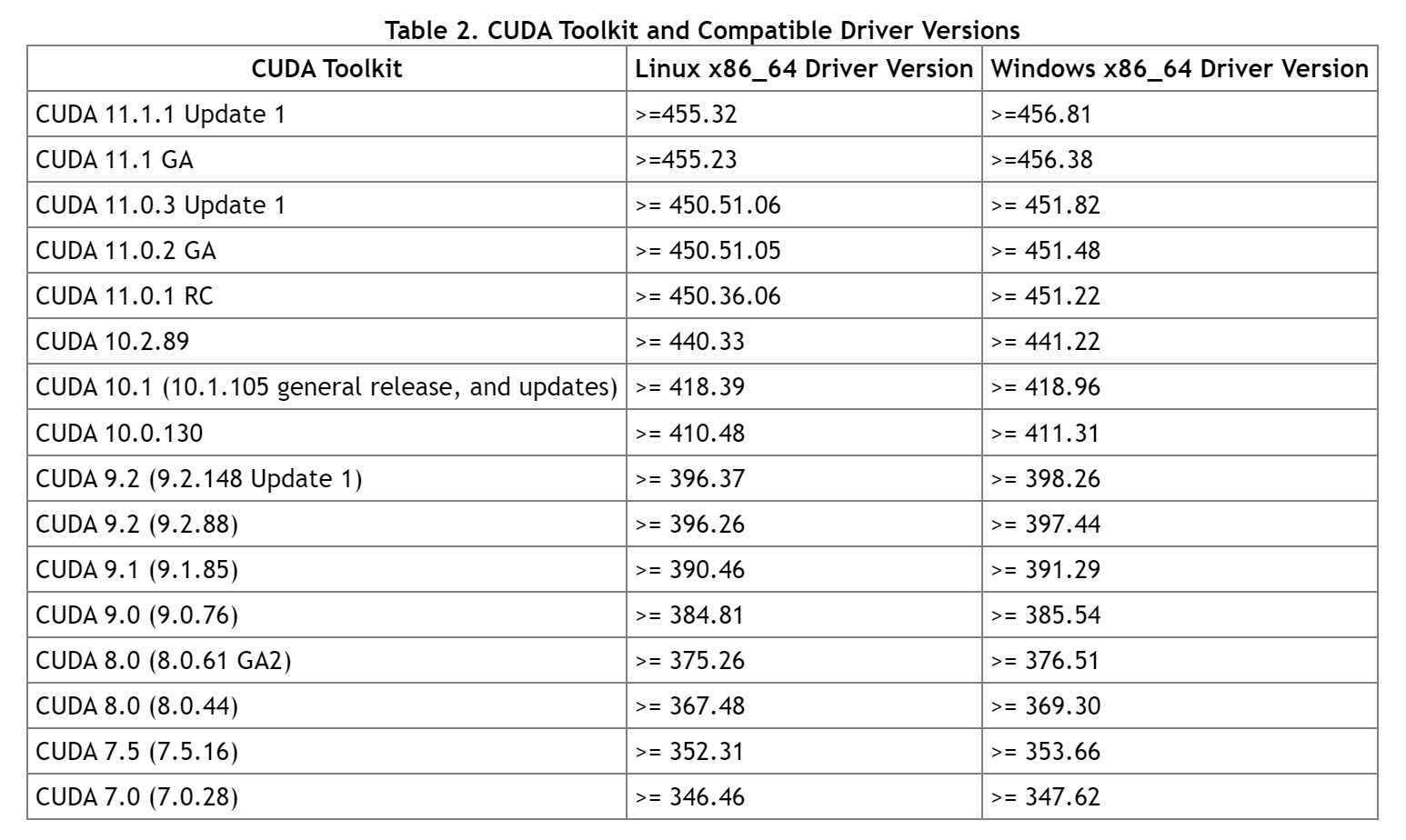
我们电脑上的 nVidia 驱动版本目前是 455.23,看这张对照表实际上应该安装 cuda 11.1 及以上才可行。(但为什么 cudatoolkit 11.0 就可以了呢?这个没具体了解,如果有了解的小伙伴可以相互讨论)
根据表上的信息,需要安装 cuda 11.1 的完整版,具体的安装方法也可以找别人的教程,我这里直接搬官方的安装指令过来(适用于 Ubuntu)。
安装的过程中可以只选 cuda 部分(假设之前已安装过 nVidia 驱动可不选)。
wget https://developer.download.nvidia.com/compute/cuda/11.1.0/local_installers/cuda_11.1.0_455.23.05_linux.run
sudo sh cuda_11.1.0_455.23.05_linux.run
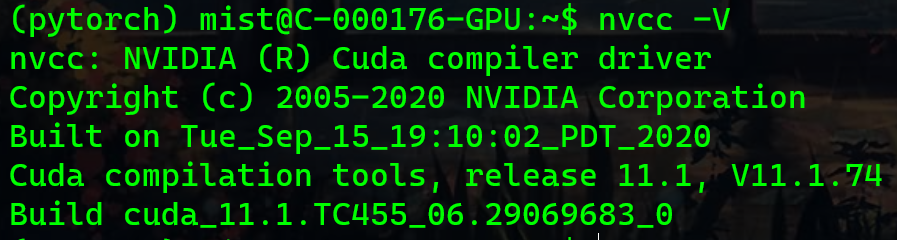
安装完毕,配置好环境变量(如果需要)后使用 nvcc -V 查看 cuda 版本信息。
如果有类似于下面的这张图,那么恭喜你安装完成。
最后一步,安装 APEX,还是上文中的那三条指令。其实你在执行指令的时候会报错,报错信息如下:
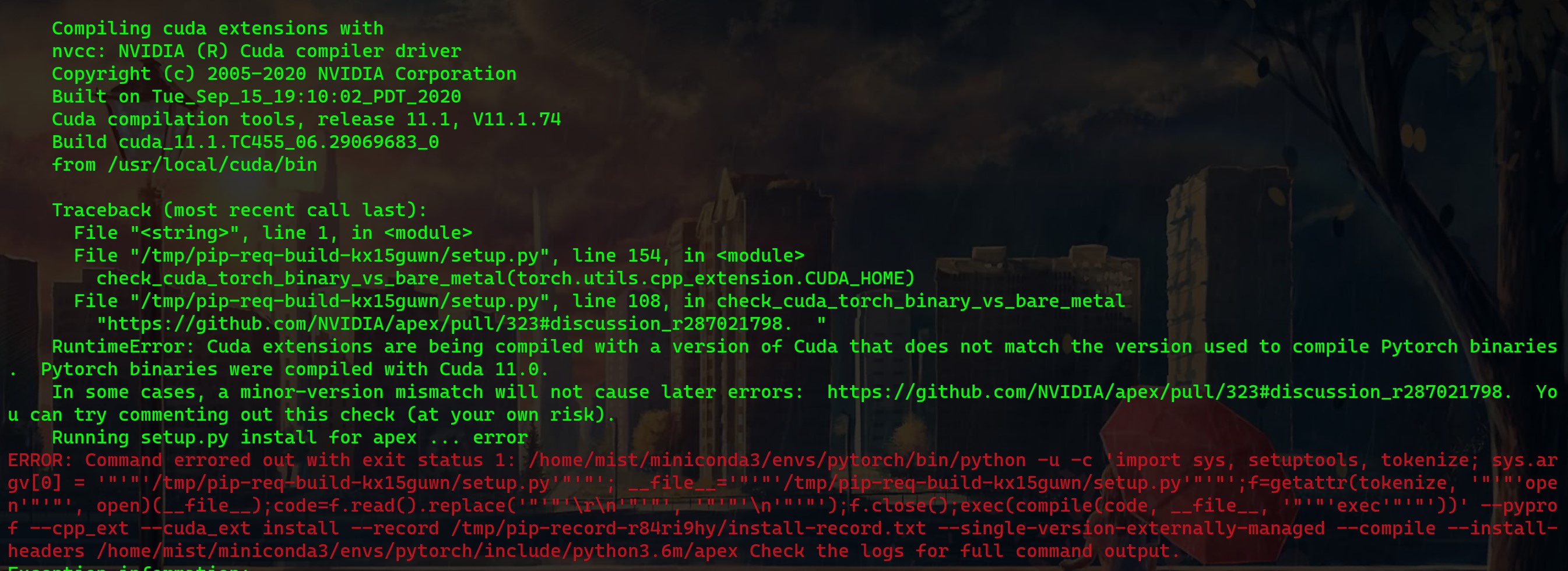
这就是刚才所纠结的问题,我们 conda 虚拟环境中的 pytorch 是基于 cuda 11.0 编译的,但此时安装的完整版 cuda 是 11.1,版本号匹配不上。
不过先别着急重新下载完整版的 cuda 11.0,因为这里也有坑,后文说。

本着 cuda 大版本差异大,小版本差异小的心态,我们直接把 apex setup.py 文件中关于版本号的校验改掉,应该就可以正常安装了。
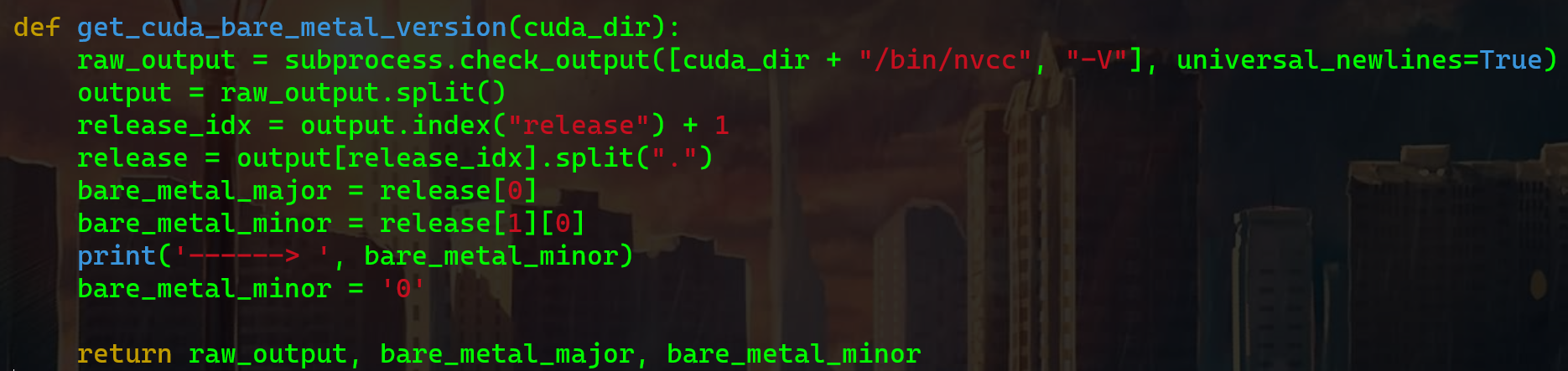
如下,找到 get_cuda_bare_metal_version 函数,其中的 bare_metal_major 是主版本,即 11;而 bare_metal_minor 是次要版本,我们需要改的就是这个,直接在下面让它等于 0 即可。
这样 pytorch 是基于 cuda 11.0 编译的,而我们完整版的 cuda 11.1 也会在 nvcc -V 识别中返回 11.0 的版本号。
校验一致,可以正常安装。
这里假如你在安装 apex 时提示类似于 apex Error : Given no hashes to check 137 links for project 'pip': discarding no candidates 时,确保不是 cuda / cudnn 版本的问题后,可通过以下方法解决。
git clone https://github.com/NVIDIA/apex
cd apex
python setup.py install
其他坑
上一节中我们提到:
不过先别着急重新下载完整版的 cuda 11.0,因为这里也有坑,后文说。
我尝试安装了 cuda 11.0,然后在编译安装 apex 时版本号的确校验过了,但是会有如下错误:
nvcc fatal : Unsupported gpu architecture 'compute_86'
猜测是 cuda 11.0 不支持 RTX 3090 这张卡,从这一步中想要继续也许可行,具体的方法可自行查阅。
RTX 3090 vs TITAN RTX vs V100 (16 GB)
这里放一组使用 RTX 3090、TITAN RTX 以及 V100 (16 GB) 在单纯 ALBERT-base 下训练与微调速度的测试对比。
实验数据仅作参考,并非权威数据。实验参数直接搬当时代码里的参数过来,max_seq_length 是允许 tokenizer 返回的最大句子长度。
args = {
'batch_size': 4,
'test_batch_size': 4,
'accumulation_steps': 1,
'lr': 0.001,
'fine_tune_lr': 0.000005,
'adam_epsilon': 0.000001,
'weight_decay': 0.01,
'epochs': 4,
'fine_tune_epochs': 2,
'max_seq_length': 512,
}
实验数据(train 和 finetune 阶段是什么可不必在意)
| 显卡 | train 阶段 | finetune 阶段 |
|---|---|---|
| RTX 3090 | 11.84 it/s | 4.32 it/s |
| TITAN RTX | 6.47 it/s | 2.39 it/s |
| V100 (16 GB) | 7.34 it/s | 2.69 it/s |
看上去 RTX 3090 真的很香,价格仅是 TITAN RTX 的一半 🤣
附上一些数据



3090哇!!(☆ω☆)
呜呜呜,羡慕空气卡
3090现在淘宝我看都快2w了学长买的时候多少钱,自己买的么Σ(‘◉⌓◉’)(。•ˇ‸ˇ•。)
我当时联系的时候商家说是 1w2,的确涨价涨的太快了。我也没买,这个是租的,呜呜,当时就应该买下来的,算是理财产品
博主的博客网站是自己写的吗,我也梦想着有一个属于自己的博客网站,真的好喜欢这种可以diy的东西,很有新鲜感显得与众不同,同时做完以后也成就感爆棚!别人的博客网站总是别人的,自己在自己写的博客网站是发表文章真的感受是不一样的,真的做的太好看了。我觉得你的生活状态就是我想要的,努力工作,同时也作者自己感兴趣的东西,努力赚钱的同时也有着自己的生活,真的太好了
基于 word press 搭建的,如果你也想搭建的话网上有一键式建站教程,像阿里云、腾讯云之类的也提供相应的服务,搭建起来特别容易,不过 DIY 成自己喜欢的样子不一定轻松了。
哈哈,学生时代第一次接触的确感觉很与众不同,成就感特别爆棚,每天都想上去看一看。不过工作或者读研以后,自己的精力放在别处时便更新的也慢了,也不想做太多的修改。所以趁着自己有时间还有精力可以好好学着做做,以后可能就没有那种心情了。(☆ω☆)